JupyterHub#
JupyterHub is the best way to serve Jupyter notebook for multiple users. Because JupyterHub manages a separate Jupyter environment for each user, it can be used in a class of students, a corporate data science group, or a scientific research group. It is a multi-user Hub that spawns, manages, and proxies multiple instances of the single-user Jupyter notebook server.
Distributions#
JupyterHub can be used in a collaborative environment by both small (0-100 users) and large teams (more than 100 users) such as a class of students, corporate data science group or scientific research group. It has two main distributions which are developed to serve the needs of each of these teams respectively.
The Littlest JupyterHub distribution is suitable if you need a small number of users (1-100) and a single server with a simple environment.
Zero to JupyterHub with Kubernetes allows you to deploy dynamic servers on the cloud if you need even more users. This distribution runs JupyterHub on top of Kubernetes.
Note
It is important to evaluate these distributions before you can continue with the configuration of JupyterHub.
Subsystems#
JupyterHub is made up of four subsystems:
a Hub (tornado process) that is the heart of JupyterHub
a configurable http proxy (node-http-proxy) that receives the requests from the client’s browser
multiple single-user Jupyter notebook servers (Python/IPython/tornado) that are monitored by Spawners
an authentication class that manages how users can access the system
Additionally, optional configurations can be added through a config.py file and manage users
kernels on an admin panel. A simplification of the whole system is displayed in the figure below:
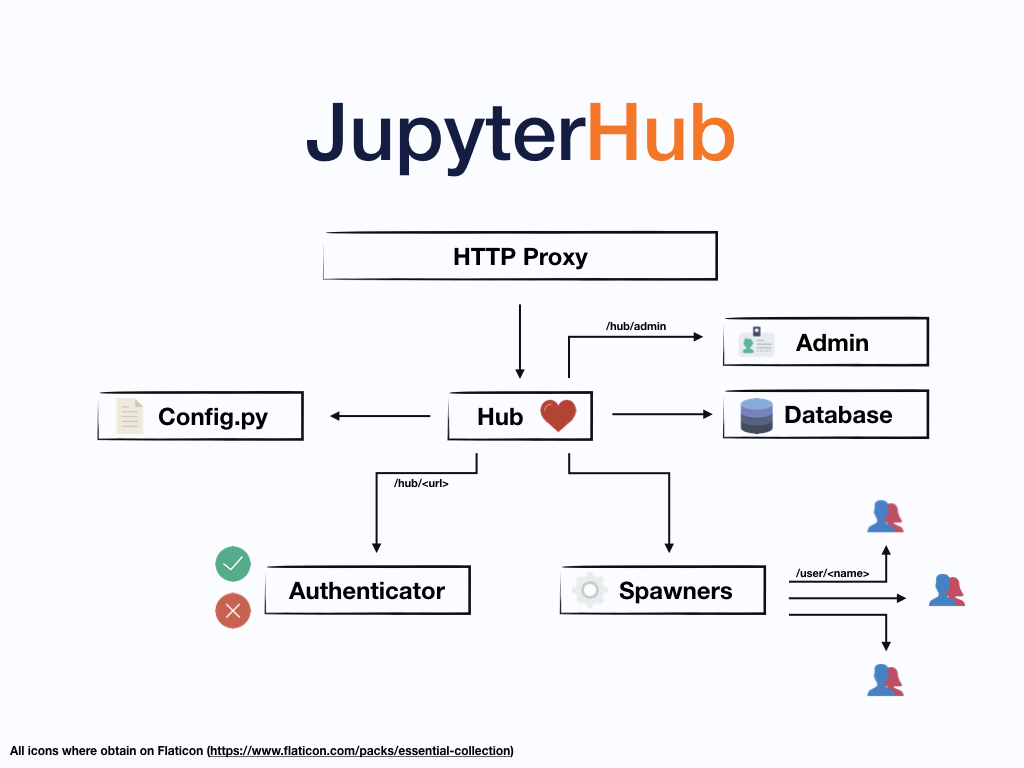
JupyterHub performs the following functions:
The Hub launches a proxy
The proxy forwards all requests to the Hub by default
The Hub handles user login and spawns single-user servers on demand
The Hub configures the proxy to forward URL prefixes to the single-user notebook servers
For convenient administration of the Hub, its users, and services, JupyterHub also provides a REST API.
The JupyterHub team and Project Jupyter value our community, and JupyterHub follows the Jupyter Community Guides.
Documentation structure#
Tutorials#
This section of the documentation contains step-by-step tutorials that help outline the capabilities of JupyterHub and how you can achieve specific aims, such as installing it. The tutorials are recommended if you do not have much experience with JupyterHub.
How-to guides#
The How-to guides provide more in-depth details than the tutorials. They are recommended for those already familiar with JupyterHub and have a specific goal. The guides help answer the question “How do I …?” based on a particular topic.
Explanation#
The Explanation section provides further details that can be used to better understand JupyterHub, such as how it can be used and configured. They are intended for those seeking to expand their knowledge of JupyterHub.
Reference#
The Reference section provides technical information about JupyterHub, such as monitoring the state of your installation and working with JupyterHub’s API modules and classes.
Frequently asked questions#
Find answers to the most frequently asked questions about JupyterHub such as how to troubleshoot an issue.
Contributing#
JupyterHub welcomes all contributors, whether you are new to the project or know your way around. The Contributing section provides information on how you can make your contributions.
Indices and tables#
Questions? Suggestions?#
All questions and suggestions are welcome. Please feel free to use our Jupyter Discourse Forum to contact our team.
Looking forward to hearing from you!