Configuring user environments#
To deploy JupyterHub means you are providing Jupyter notebook environments for multiple users. Often, this includes a desire to configure the user environment in a custom way.
Since the jupyterhub-singleuser server extends the standard Jupyter notebook
server, most configuration and documentation that applies to Jupyter Notebook
applies to the single-user environments. Configuration of user environments
typically does not occur through JupyterHub itself, but rather through system-wide
configuration of Jupyter, which is inherited by jupyterhub-singleuser.
Tip: When searching for configuration tips for JupyterHub user environments, you might want to remove JupyterHub from your search because there are a lot more people out there configuring Jupyter than JupyterHub and the configuration is the same.
This section will focus on user environments, which includes the following:
Installing packages#
To make packages available to users, you will typically install packages system-wide or in a shared environment.
This installation location should always be in the same environment where
jupyterhub-singleuser itself is installed in, and must be readable and
executable by your users. If you want your users to be able to install additional
packages, the installation location must also be writable by your users.
If you are using a standard Python installation on your system, use the following command:
sudo python3 -m pip install numpy
to install the numpy package in the default Python 3 environment on your system
(typically /usr/local).
You may also use conda to install packages. If you do, you should make sure that the conda environment has appropriate permissions for users to be able to run Python code in the env. The env must be readable and executable by all users. Additionally it must be writeable if you want users to install additional packages.
Configuring Jupyter and IPython#
Jupyter and IPython have their own configuration systems.
As a JupyterHub administrator, you will typically want to install and configure environments for all JupyterHub users. For example, let’s say you wish for each student in a class to have the same user environment configuration.
Jupyter and IPython support “system-wide” locations for configuration, which is the logical place to put global configuration that you want to affect all users. It’s generally more efficient to configure user environments “system-wide”, and it’s a good practice to avoid creating files in the users’ home directories. The typical locations for these config files are:
system-wide in
/etc/{jupyter|ipython}env-wide (environment wide) in
{sys.prefix}/etc/{jupyter|ipython}.
Jupyter environment configuration priority#
When Jupyter runs in an environment (conda or virtualenv), it prefers to load configuration from the environment over each user’s own configuration (e.g. in ~/.jupyter).
This may cause issues if you use a shared conda environment or virtualenv for users, because e.g. jupyterlab may try to write information like workspaces or settings to the environment instead of the user’s own directory.
This could fail with something like Permission denied: $PREFIX/etc/jupyter/lab.
To avoid this issue, set JUPYTER_PREFER_ENV_PATH=0 in the user environment:
c.Spawner.environment.update(
{
"JUPYTER_PREFER_ENV_PATH": "0",
}
)
which tells Jupyter to prefer user configuration paths (e.g. in ~/.jupyter) to configuration set in the environment.
Example: Enable an extension system-wide#
For example, to enable the cython IPython extension for all of your users, create the file /etc/ipython/ipython_config.py:
c.InteractiveShellApp.extensions.append("cython")
Example: Enable a Jupyter notebook configuration setting for all users#
Note
These examples configure the Jupyter ServerApp, which is used by JupyterLab, the default in JupyterHub 2.0.
If you are using the classing Jupyter Notebook server, the same things should work, with the following substitutions:
Search for
jupyter_server_config, and replace withjupyter_notebook_configSearch for
NotebookApp, and replace withServerApp
To enable Jupyter notebook’s internal idle-shutdown behavior (requires notebook ≥ 5.4), set the following in the /etc/jupyter/jupyter_server_config.py file:
# shutdown the server after no activity for an hour
c.ServerApp.shutdown_no_activity_timeout = 60 * 60
# shutdown kernels after no activity for 20 minutes
c.MappingKernelManager.cull_idle_timeout = 20 * 60
# check for idle kernels every two minutes
c.MappingKernelManager.cull_interval = 2 * 60
Installing kernelspecs#
You may have multiple Jupyter kernels installed and want to make sure that they are available to all of your users. This means installing kernelspecs either system-wide (e.g. in /usr/local/) or in the sys.prefix of JupyterHub
itself.
Jupyter kernelspec installation is system-wide by default, but some kernels may default to installing kernelspecs in your home directory. These will need to be moved system-wide to ensure that they are accessible.
To see where your kernelspecs are, you can use the following command:
jupyter kernelspec list
Example: Installing kernels system-wide#
Let’s assume that I have a Python 2 and Python 3 environment that I want to make sure are available, I can install their specs system-wide (in /usr/local) using the following command:
/path/to/python3 -m ipykernel install --prefix=/usr/local
/path/to/python2 -m ipykernel install --prefix=/usr/local
Multi-user hosts vs. Containers#
There are two broad categories of user environments that depend on what Spawner you choose:
Multi-user hosts (shared system)
Container-based
How you configure user environments for each category can differ a bit depending on what Spawner you are using.
The first category is a shared system (multi-user host) where
each user has a JupyterHub account, a home directory as well as being
a real system user. In this example, shared configuration and installation
must be in a ‘system-wide’ location, such as /etc/, or /usr/local
or a custom prefix such as /opt/conda.
When JupyterHub uses container-based Spawners (e.g. KubeSpawner or DockerSpawner), the ‘system-wide’ environment is really the container image used for users.
In both cases, you want to avoid putting configuration in user home directories because users can change those configuration settings. Also, home directories typically persist once they are created, thereby making it difficult for admins to update later.
Named servers#
By default, in a JupyterHub deployment, each user has one server only.
JupyterHub can, however, have multiple servers per user. This is mostly useful in deployments where users can configure the environment in which their server will start (e.g. resource requests on an HPC cluster), so that a given user can have multiple configurations running at the same time, without having to stop and restart their own server.
To allow named servers, include this code snippet in your config file:
c.JupyterHub.allow_named_servers = True
Named servers were implemented in the REST API in JupyterHub 0.8, and JupyterHub 1.0 introduces UI for managing named servers via the user home page:
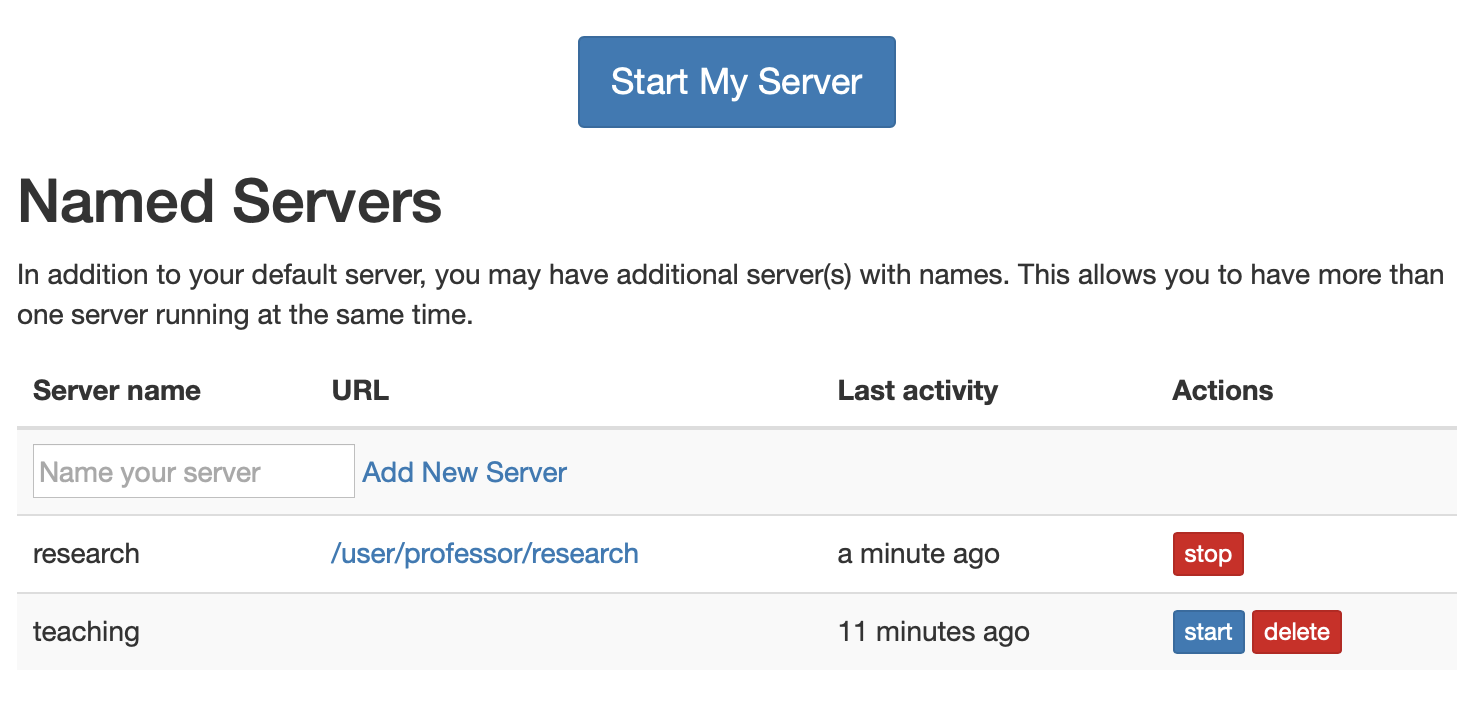
as well as the admin page:
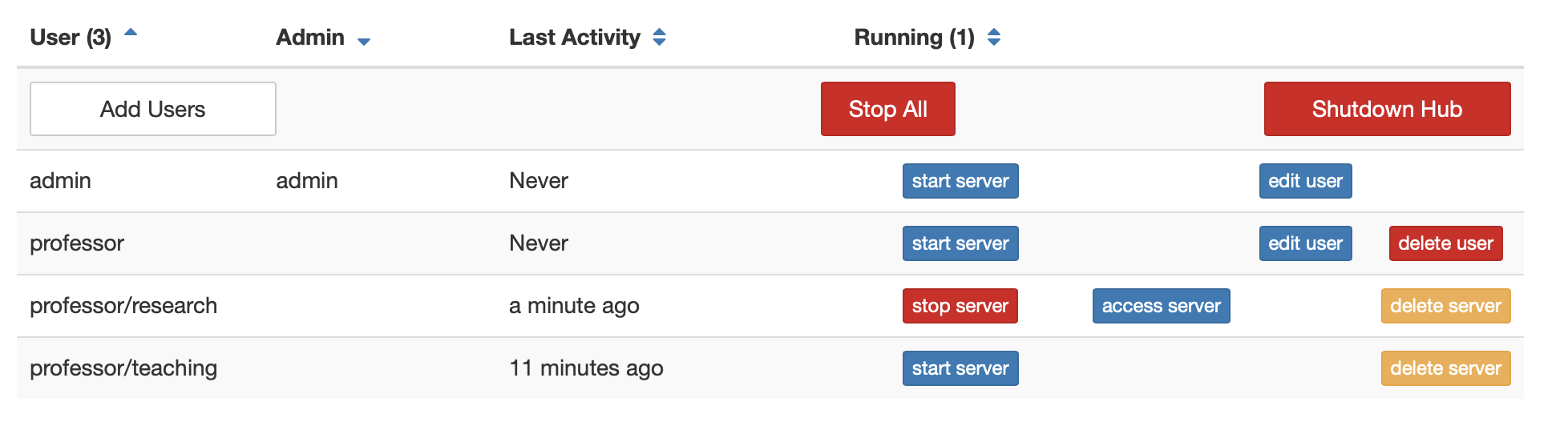
Named servers can be accessed, created, started, stopped, and deleted from these pages. Activity tracking is now per server as well.
To limit the number of named server per user by setting a constant value, include this code snippet in your config file:
c.JupyterHub.named_server_limit_per_user = 5
Alternatively, to use a callable/awaitable based on the handler object, include this code snippet in your config file:
def named_server_limit_per_user_fn(handler):
user = handler.current_user
if user and user.admin:
return 0
return 5
c.JupyterHub.named_server_limit_per_user = named_server_limit_per_user_fn
This can be useful for quota service implementations. The example above limits the number of named servers for non-admin users only.
If named_server_limit_per_user is set to 0, no limit is enforced.
When using named servers, Spawners may need additional configuration to take the servername into account. Whilst KubeSpawner takes the servername into account by default in pod_name_template, other Spawners may not. Check the documentation for the specific Spawner to see how singleuser servers are named, for example in DockerSpawner this involves modifying the name_template setting to include servername, eg. "{prefix}-{username}-{servername}".
Switching back to the classic notebook#
By default, the single-user server launches JupyterLab, which is based on Jupyter Server.
This is the default server when running JupyterHub ≥ 2.0.
To switch to using the legacy Jupyter Notebook server (notebook < 7.0), you can set the JUPYTERHUB_SINGLEUSER_APP environment variable
(in the single-user environment) to:
export JUPYTERHUB_SINGLEUSER_APP='notebook.notebookapp.NotebookApp'
Note
JUPYTERHUB_SINGLEUSER_APP='notebook.notebookapp.NotebookApp'
is only valid for notebook < 7. notebook v7 is based on jupyter-server,
and the default jupyter-server application must be used.
Selecting the new notebook UI is no longer a matter of selecting the server app to launch,
but only the default URL for users to visit.
To use notebook v7 with JupyterHub, leave the default singleuser app config alone (or specify JUPYTERHUB_SINGLEUSER_APP=jupyter-server) and set the default URL for user servers:
c.Spawner.default_url = '/tree/'
Changed in version 2.0: JupyterLab is now the default single-user UI, if available,
which is based on the Jupyter Server,
no longer the legacy Jupyter Notebook server.
JupyterHub prior to 2.0 launched the legacy notebook server (jupyter notebook),
and the Jupyter server could be selected by specifying the following:
# jupyterhub_config.py
c.Spawner.cmd = ["jupyter-labhub"]
Alternatively, for an otherwise customized Jupyter Server app, set the environment variable using the following command:
export JUPYTERHUB_SINGLEUSER_APP='jupyter_server.serverapp.ServerApp'