Getting started with JupyterHub¶
This section contains getting started information on the following topics:
- Technical Overview
- Installation
- Configuration
- Networking
- Security
- Authentication and users
- Spawners and single-user notebook servers
- External Services
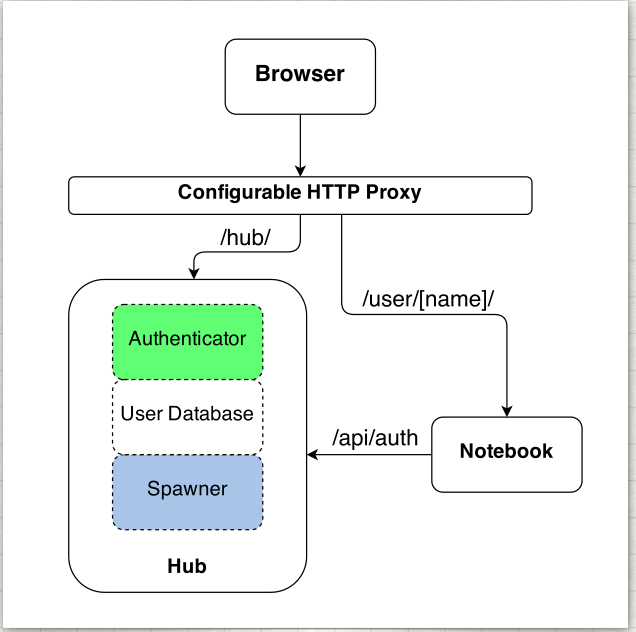
Technical Overview¶
JupyterHub is a set of processes that together provide a single user Jupyter Notebook server for each person in a group.
Three subsystems¶
Three major subsystems run by the jupyterhub command line program:
- Single-User Notebook Server: a dedicated, single-user, Jupyter Notebook server is started for each user on the system when the user logs in. The object that starts these servers is called a Spawner.
- Proxy: the public facing part of JupyterHub that uses a dynamic proxy to route HTTP requests to the Hub and Single User Notebook Servers.
- Hub: manages user accounts, authentication, and coordinates Single User Notebook Servers using a Spawner.
Deployment server¶
To use JupyterHub, you need a Unix server (typically Linux) running somewhere that is accessible to your team on the network. The JupyterHub server can be on an internal network at your organization, or it can run on the public internet (in which case, take care with the Hub’s security).
Basic operation¶
Users access JupyterHub through a web browser, by going to the IP address or the domain name of the server.
Basic principles of operation:
- Hub spawns proxy
- Proxy forwards all requests to hub by default
- Hub handles login, and spawns single-user servers on demand
- Hub configures proxy to forward url prefixes to single-user servers
Different authenticators control access to JupyterHub. The default one (PAM) uses the user accounts on the server where JupyterHub is running. If you use this, you will need to create a user account on the system for each user on your team. Using other authenticators, you can allow users to sign in with e.g. a GitHub account, or with any single-sign-on system your organization has.
Next, spawners control how JupyterHub starts the individual notebook server for each user. The default spawner will start a notebook server on the same machine running under their system username. The other main option is to start each server in a separate container, often using Docker.
Default behavior¶
IMPORTANT: You should not run JupyterHub without SSL encryption on a public network.
See Security documentation for how to configure JupyterHub to use SSL, or put it behind SSL termination in another proxy server, such as nginx.
Deprecation note: Removed --no-ssl in version 0.7.
JupyterHub versions 0.5 and 0.6 require extra confirmation via --no-ssl to
allow running without SSL using the command jupyterhub --no-ssl. The
--no-ssl command line option is not needed anymore in version 0.7.
To start JupyterHub in its default configuration, type the following at the command line:
sudo jupyterhub
The default Authenticator that ships with JupyterHub authenticates users with their system name and password (via PAM). Any user on the system with a password will be allowed to start a single-user notebook server.
The default Spawner starts servers locally as each user, one dedicated server per user. These servers listen on localhost, and start in the given user’s home directory.
By default, the Proxy listens on all public interfaces on port 8000. Thus you can reach JupyterHub through either:
http://localhost:8000- or any other public IP or domain pointing to your system.
In their default configuration, the other services, the Hub and Single-User Servers, all communicate with each other on localhost only.
By default, starting JupyterHub will write two files to disk in the current working directory:
jupyterhub.sqliteis the sqlite database containing all of the state of the Hub. This file allows the Hub to remember what users are running and where, as well as other information enabling you to restart parts of JupyterHub separately. It is important to note that this database contains no sensitive information other than Hub usernames.jupyterhub_cookie_secretis the encryption key used for securing cookies. This file needs to persist in order for restarting the Hub server to avoid invalidating cookies. Conversely, deleting this file and restarting the server effectively invalidates all login cookies. The cookie secret file is discussed in the Cookie Secret documentation.
The location of these files can be specified via configuration, discussed below.
Installation¶
See the project’s README for help installing JupyterHub.
Planning your installation¶
Prior to beginning installation, it’s helpful to consider some of the following:
- deployment system (bare metal, Docker)
- Authentication (PAM, OAuth, etc.)
- Spawner of singleuser notebook servers (Docker, Batch, etc.)
- Services (nbgrader, etc.)
- JupyterHub database (default SQLite; traditional RDBMS such as PostgreSQL,) MySQL, or other databases supported by SQLAlchemy)
Folders and File Locations¶
It is recommended to put all of the files used by JupyterHub into standard UNIX filesystem locations.
/srv/jupyterhubfor all security and runtime files/etc/jupyterhubfor all configuration files/var/logfor log files
Configuration¶
JupyterHub is configured in two ways:
- Configuration file
- Command-line arguments
Configuration file¶
By default, JupyterHub will look for a configuration file (which may not be created yet)
named jupyterhub_config.py in the current working directory.
You can create an empty configuration file with:
jupyterhub --generate-config
This empty configuration file has descriptions of all configuration variables and their default values. You can load a specific config file with:
jupyterhub -f /path/to/jupyterhub_config.py
See also: general docs on the config system Jupyter uses.
Command-line arguments¶
Type the following for brief information about the command-line arguments:
jupyterhub -h
or:
jupyterhub --help-all
for the full command line help.
All configurable options are technically configurable on the command-line,
even if some are really inconvenient to type. Just replace the desired option,
c.Class.trait, with --Class.trait. For example, to configure the
c.Spawner.notebook_dir trait from the command-line:
jupyterhub --Spawner.notebook_dir='~/assignments'
Networking¶
Configuring the Proxy’s IP address and port¶
The Proxy’s main IP address setting determines where JupyterHub is available to users.
By default, JupyterHub is configured to be available on all network interfaces
('') on port 8000. Note: Use of '*' is discouraged for IP configuration;
instead, use of '0.0.0.0' is preferred.
Changing the IP address and port can be done with the following command line arguments:
jupyterhub --ip=192.168.1.2 --port=443
Or by placing the following lines in a configuration file:
c.JupyterHub.ip = '192.168.1.2'
c.JupyterHub.port = 443
Port 443 is used as an example since 443 is the default port for SSL/HTTPS.
Configuring only the main IP and port of JupyterHub should be sufficient for most deployments of JupyterHub. However, more customized scenarios may need additional networking details to be configured.
Configuring the Proxy’s REST API communication IP address and port (optional)¶
The Hub service talks to the proxy via a REST API on a secondary port, whose network interface and port can be configured separately. By default, this REST API listens on port 8081 of localhost only.
If running the Proxy separate from the Hub, configure the REST API communication IP address and port with:
# ideally a private network address
c.JupyterHub.proxy_api_ip = '10.0.1.4'
c.JupyterHub.proxy_api_port = 5432
Configuring the Hub if Spawners or Proxy are remote or isolated in containers¶
The Hub service also listens only on localhost (port 8080) by default. The Hub needs needs to be accessible from both the proxy and all Spawners. When spawning local servers, an IP address setting of localhost is fine. If either the Proxy or (more likely) the Spawners will be remote or isolated in containers, the Hub must listen on an IP that is accessible.
c.JupyterHub.hub_ip = '10.0.1.4'
c.JupyterHub.hub_port = 54321
Security¶
IMPORTANT: You should not run JupyterHub without SSL encryption on a public network.
Deprecation note: Removed --no-ssl in version 0.7.
JupyterHub versions 0.5 and 0.6 require extra confirmation via --no-ssl to
allow running without SSL using the command jupyterhub --no-ssl. The
--no-ssl command line option is not needed anymore in version 0.7.
Security is the most important aspect of configuring Jupyter. There are four main aspects of the security configuration:
- SSL encryption (to enable HTTPS)
- Cookie secret (a key for encrypting browser cookies)
- Proxy authentication token (used for the Hub and other services to authenticate to the Proxy)
- Periodic security audits
Note that the Hub hashes all secrets (e.g., auth tokens) before storing them in its database. A loss of control over read-access to the database should have no security impact on your deployment.
SSL encryption¶
Since JupyterHub includes authentication and allows arbitrary code execution, you should not run it without SSL (HTTPS). This will require you to obtain an official, trusted SSL certificate or create a self-signed certificate. Once you have obtained and installed a key and certificate you need to specify their locations in the configuration file as follows:
c.JupyterHub.ssl_key = '/path/to/my.key'
c.JupyterHub.ssl_cert = '/path/to/my.cert'
It is also possible to use letsencrypt (https://letsencrypt.org/) to obtain
a free, trusted SSL certificate. If you run letsencrypt using the default
options, the needed configuration is (replace mydomain.tld by your fully
qualified domain name):
c.JupyterHub.ssl_key = '/etc/letsencrypt/live/{mydomain.tld}/privkey.pem'
c.JupyterHub.ssl_cert = '/etc/letsencrypt/live/{mydomain.tld}/fullchain.pem'
If the fully qualified domain name (FQDN) is example.com, the following
would be the needed configuration:
c.JupyterHub.ssl_key = '/etc/letsencrypt/live/example.com/privkey.pem'
c.JupyterHub.ssl_cert = '/etc/letsencrypt/live/example.com/fullchain.pem'
Some cert files also contain the key, in which case only the cert is needed. It is important that these files be put in a secure location on your server, where they are not readable by regular users.
Note on chain certificates: If you are using a chain certificate, see also chained certificate for SSL in the JupyterHub troubleshooting FAQ).
Note: In certain cases, e.g. behind SSL termination in nginx, allowing no SSL running on the hub may be desired.
Cookie secret¶
The cookie secret is an encryption key, used to encrypt the browser cookies used for authentication. If this value changes for the Hub, all single-user servers must also be restarted. Normally, this value is stored in a file, the location of which can be specified in a config file as follows:
c.JupyterHub.cookie_secret_file = '/srv/jupyterhub/cookie_secret'
The content of this file should be a long random string encoded in MIME Base64. An example would be to generate this file as:
openssl rand -base64 2048 > /srv/jupyterhub/cookie_secret
In most deployments of JupyterHub, you should point this to a secure location on the file
system, such as /srv/jupyterhub/cookie_secret. If the cookie secret file doesn’t exist when
the Hub starts, a new cookie secret is generated and stored in the file. The
file must not be readable by group or other or the server won’t start.
The recommended permissions for the cookie secret file are 600 (owner-only rw).
If you would like to avoid the need for files, the value can be loaded in the Hub process from
the JPY_COOKIE_SECRET environment variable, which is a hex-encoded string. You
can set it this way:
export JPY_COOKIE_SECRET=`openssl rand -hex 1024`
For security reasons, this environment variable should only be visible to the Hub. If you set it dynamically as above, all users will be logged out each time the Hub starts.
You can also set the cookie secret in the configuration file itself,jupyterhub_config.py,
as a binary string:
c.JupyterHub.cookie_secret = bytes.fromhex('VERY LONG SECRET HEX STRING')
Proxy authentication token¶
The Hub authenticates its requests to the Proxy using a secret token that
the Hub and Proxy agree upon. The value of this string should be a random
string (for example, generated by openssl rand -hex 32). You can pass
this value to the Hub and Proxy using either the CONFIGPROXY_AUTH_TOKEN
environment variable:
export CONFIGPROXY_AUTH_TOKEN=`openssl rand -hex 32`
This environment variable needs to be visible to the Hub and Proxy.
Or you can set the value in the configuration file, jupyterhub_config.py:
c.JupyterHub.proxy_auth_token = '0bc02bede919e99a26de1e2a7a5aadfaf6228de836ec39a05a6c6942831d8fe5'
If you don’t set the Proxy authentication token, the Hub will generate a random key itself, which means that any time you restart the Hub you must also restart the Proxy. If the proxy is a subprocess of the Hub, this should happen automatically (this is the default configuration).
Another time you must set the Proxy authentication token yourself is if you want other services, such as nbgrader to also be able to connect to the Proxy.
Security audits¶
We recommend that you do periodic reviews of your deployment’s security. It’s good practice to keep JupyterHub, configurable-http-proxy, and nodejs versions up to date.
A handy website for testing your deployment is Qualsys’ SSL analyzer tool.
Authentication and users¶
The default Authenticator uses PAM to authenticate system users with their username and password. The default behavior of this Authenticator is to allow any user with an account and password on the system to login.
Creating a whitelist of users¶
You can restrict which users are allowed to login with Authenticator.whitelist:
c.Authenticator.whitelist = {'mal', 'zoe', 'inara', 'kaylee'}
Managing Hub administrators¶
Admin users of JupyterHub have the ability to take actions on users’ behalf, such as stopping and restarting their servers, and adding and removing new users from the whitelist. Any users in the admin list are automatically added to the whitelist, if they are not already present. The set of initial Admin users can configured as follows:
c.Authenticator.admin_users = {'mal', 'zoe'}
If JupyterHub.admin_access is True (not default),
then admin users have permission to log in as other users on their respective machines, for debugging.
You should make sure your users know if admin_access is enabled.
Note: additional configuration examples are provided in this guide’s Configuration Examples section.
Add or remove users from the Hub¶
Users can be added and removed to the Hub via the admin panel or REST API. These users will be added to the whitelist and database. Restarting the Hub will not require manually updating the whitelist in your config file, as the users will be loaded from the database. This means that after starting the Hub once, it is not sufficient to remove users from the whitelist in your config file. You must also remove them from the database, either by discarding the database file, or via the admin UI.
The default PAMAuthenticator is one case of a special kind of authenticator, called a
LocalAuthenticator, indicating that it manages users on the local system. When you add a user to
the Hub, a LocalAuthenticator checks if that user already exists. Normally, there will be an
error telling you that the user doesn’t exist. If you set the configuration value
c.LocalAuthenticator.create_system_users = True
however, adding a user to the Hub that doesn’t already exist on the system will result in the Hub
creating that user via the system adduser command line tool. This option is typically used on
hosted deployments of JupyterHub, to avoid the need to manually create all your users before
launching the service. It is not recommended when running JupyterHub in situations where
JupyterHub users maps directly onto UNIX users.
Spawners and single-user notebook servers¶
Since the single-user server is an instance of jupyter notebook, an entire separate
multi-process application, there are many aspect of that server can configure, and a lot of ways
to express that configuration.
At the JupyterHub level, you can set some values on the Spawner. The simplest of these is
Spawner.notebook_dir, which lets you set the root directory for a user’s server. This root
notebook directory is the highest level directory users will be able to access in the notebook
dashboard. In this example, the root notebook directory is set to ~/notebooks, where ~ is
expanded to the user’s home directory.
c.Spawner.notebook_dir = '~/notebooks'
You can also specify extra command-line arguments to the notebook server with:
c.Spawner.args = ['--debug', '--profile=PHYS131']
This could be used to set the users default page for the single user server:
c.Spawner.args = ['--NotebookApp.default_url=/notebooks/Welcome.ipynb']
Since the single-user server extends the notebook server application,
it still loads configuration from the ipython_notebook_config.py config file.
Each user may have one of these files in $HOME/.ipython/profile_default/.
IPython also supports loading system-wide config files from /etc/ipython/,
which is the place to put configuration that you want to affect all of your users.
External services¶
JupyterHub has a REST API that can be used by external services like the
cull_idle_servers
script which monitors and kills idle single-user servers periodically. In order to run such an
external service, you need to provide it an API token. In the case of cull_idle_servers, it is passed
as the environment variable called JPY_API_TOKEN.
Currently there are two ways of registering that token with JupyterHub. The first one is to use
the jupyterhub command to generate a token for a specific hub user:
jupyterhub token <username>
As of version 0.6.0, the preferred way of doing this is to first generate an API token:
openssl rand -hex 32
and then write it to your JupyterHub configuration file (note that the key is the token while the value is the username):
c.JupyterHub.api_tokens = {'token' : 'username'}
Upon restarting JupyterHub, you should see a message like below in the logs:
Adding API token for <username>
Now you can run your script, i.e. cull_idle_servers, by providing it the API token and it will authenticate through
the REST API to interact with it.