Technical Overview¶
The Technical Overview section gives you a high-level view of:
JupyterHub’s Subsystems: Hub, Proxy, Single-User Notebook Server
how the subsystems interact
the process from JupyterHub access to user login
JupyterHub’s default behavior
customizing JupyterHub
The goal of this section is to share a deeper technical understanding of JupyterHub and how it works.
The Subsystems: Hub, Proxy, Single-User Notebook Server¶
JupyterHub is a set of processes that together provide a single user Jupyter
Notebook server for each person in a group. Three major subsystems are started
by the jupyterhub command line program:
Hub (Python/Tornado): manages user accounts, authentication, and coordinates Single User Notebook Servers using a Spawner.
Proxy: the public facing part of JupyterHub that uses a dynamic proxy to route HTTP requests to the Hub and Single User Notebook Servers. configurable http proxy (node-http-proxy) is the default proxy.
Single-User Notebook Server (Python/Tornado): a dedicated, single-user, Jupyter Notebook server is started for each user on the system when the user logs in. The object that starts the single-user notebook servers is called a Spawner.
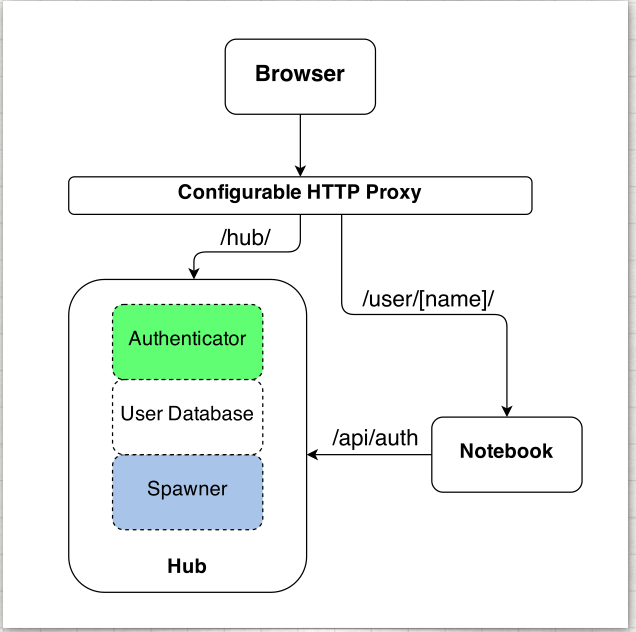
How the Subsystems Interact¶
Users access JupyterHub through a web browser, by going to the IP address or the domain name of the server.
The basic principles of operation are:
The Hub spawns the proxy (in the default JupyterHub configuration)
The proxy forwards all requests to the Hub by default
The Hub handles login, and spawns single-user notebook servers on demand
The Hub configures the proxy to forward url prefixes to single-user notebook servers
The proxy is the only process that listens on a public interface. The Hub sits
behind the proxy at /hub. Single-user servers sit behind the proxy at
/user/[username].
Different authenticators control access to JupyterHub. The default one (PAM) uses the user accounts on the server where JupyterHub is running. If you use this, you will need to create a user account on the system for each user on your team. Using other authenticators, you can allow users to sign in with e.g. a GitHub account, or with any single-sign-on system your organization has.
Next, spawners control how JupyterHub starts the individual notebook server for each user. The default spawner will start a notebook server on the same machine running under their system username. The other main option is to start each server in a separate container, often using Docker.
The Process from JupyterHub Access to User Login¶
When a user accesses JupyterHub, the following events take place:
Login data is handed to the Authenticator instance for validation
The Authenticator returns the username if the login information is valid
A single-user notebook server instance is spawned for the logged-in user
When the single-user notebook server starts, the proxy is notified to forward requests to
/user/[username]/*to the single-user notebook server.A cookie is set on
/hub/, containing an encrypted token. (Prior to version 0.8, a cookie for/user/[username]was used too.)The browser is redirected to
/user/[username], and the request is handled by the single-user notebook server.
The single-user server identifies the user with the Hub via OAuth:
on request, the single-user server checks a cookie
if no cookie is set, redirect to the Hub for verification via OAuth
after verification at the Hub, the browser is redirected back to the single-user server
the token is verified and stored in a cookie
if no user is identified, the browser is redirected back to
/hub/login
Default Behavior¶
By default, the Proxy listens on all public interfaces on port 8000. Thus you can reach JupyterHub through either:
http://localhost:8000or any other public IP or domain pointing to your system.
In their default configuration, the other services, the Hub and Single-User Notebook Servers, all communicate with each other on localhost only.
By default, starting JupyterHub will write two files to disk in the current working directory:
jupyterhub.sqliteis the SQLite database containing all of the state of the Hub. This file allows the Hub to remember which users are running and where, as well as storing other information enabling you to restart parts of JupyterHub separately. It is important to note that this database contains no sensitive information other than Hub usernames.jupyterhub_cookie_secretis the encryption key used for securing cookies. This file needs to persist so that a Hub server restart will avoid invalidating cookies. Conversely, deleting this file and restarting the server effectively invalidates all login cookies. The cookie secret file is discussed in the Cookie Secret section of the Security Settings document.
The location of these files can be specified via configuration settings. It is
recommended that these files be stored in standard UNIX filesystem locations,
such as /etc/jupyterhub for all configuration files and /srv/jupyterhub for
all security and runtime files.
Customizing JupyterHub¶
There are two basic extension points for JupyterHub:
How users are authenticated by Authenticators
How user’s single-user notebook server processes are started by Spawners
Each is governed by a customizable class, and JupyterHub ships with basic defaults for each.
To enable custom authentication and/or spawning, subclass Authenticator or
Spawner, and override the relevant methods.